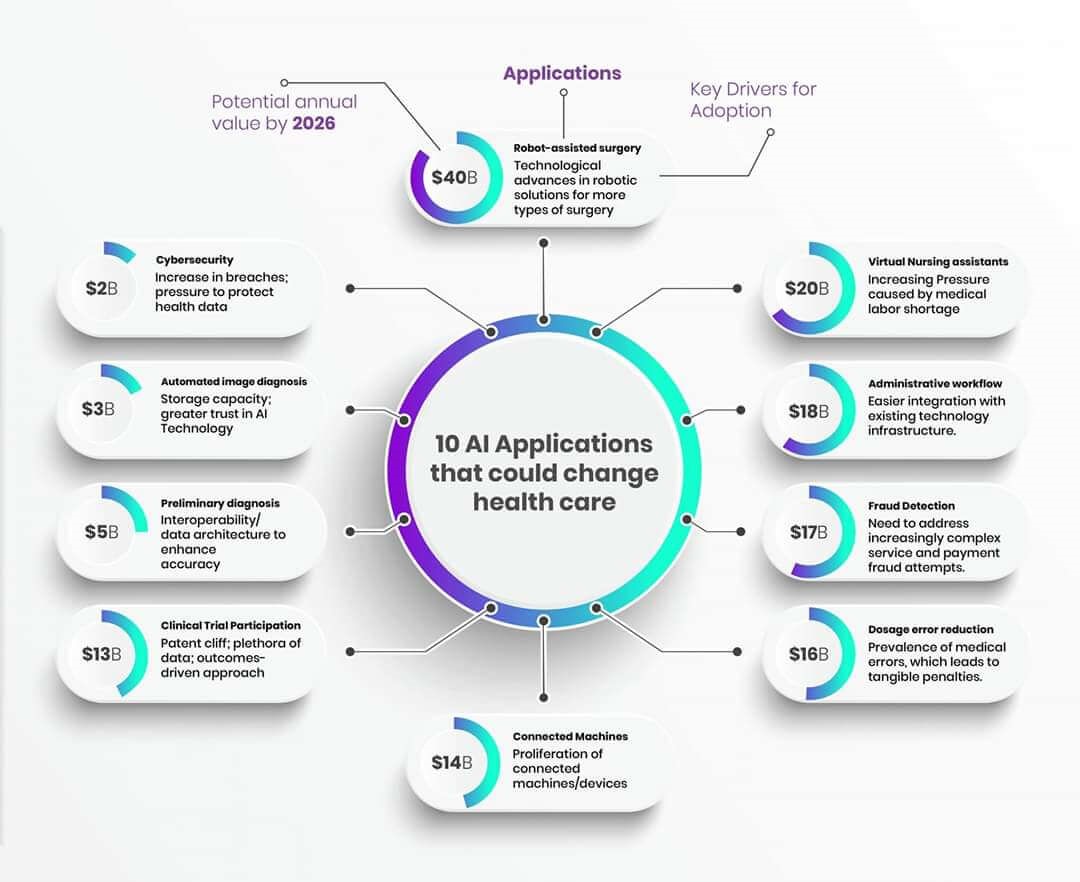
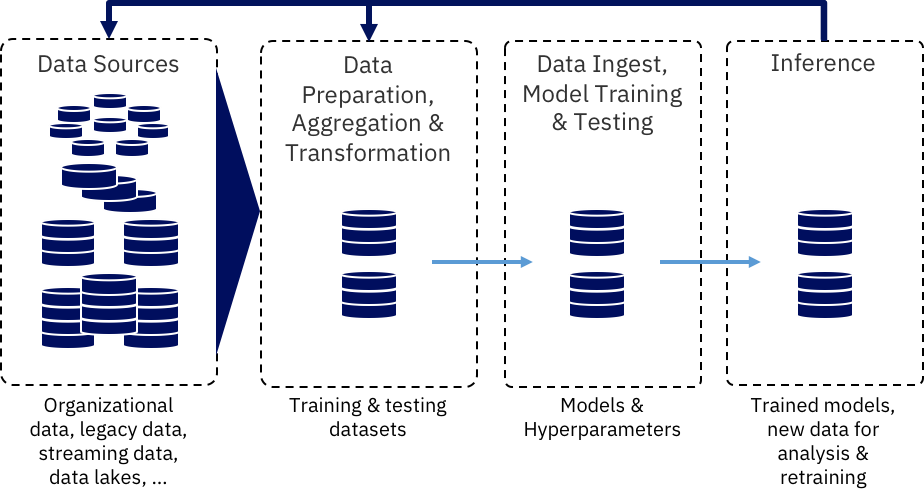
Summary: To build an efficient machine learning model for the consumer goods companies to ensure that their products are available and properly placed in stores.
The problem:
Items that are often eaten by consumers (foods, beverages, household supplies, etc.) necessitate a detailed replenishment and positioning routine at the point of sale (supermarkets, convenience stores, etc).
Researchers have frequently demonstrated over the last few years that around two-thirds of purchase choices are made after buyers enter the store. One of the most difficult tasks for consumer goods companies is to ensure that their products are available and properly placed in stores.
Teams in stores organise shelves based on marketing objectives and maintain product levels in stores. These individuals may count the number of SKUs of each brand in a store to estimate product stockpiles and market share, as well as assist in the development of marketing plans.
Preparing the data:
Gathering good data is the first step in training a decent model. As previously said, this solution will employ a dataset of SKUs in various scenarios. SKU110K was created to serve as a benchmark for models that can recognise objects in densely packed settings.
The dataset is in Pascal VOC format, which must be translated to tf.record. The conversion script can be found here, and the tf.record version of the dataset can be found in my project repository. As previously said, SKU110K is a vast and difficult dataset to work with. It has a large number of objects that are often similar, if not identical, and are arranged in close proximity.
Choosing the model:
The SKU detection problem can be solved using a number of neural networks. However, when translated to TensorFlow.js and run in real-time, the architectures that readily reach a high level of precision are quite dense and do not have tolerable inference times.
As a result, the focus here will be on optimising a mid-level neural network to attain respectable precision while working on densely packed scenes and running inferences in real-time. The task will be to tackle the problem with the lightest single-shot model available: SSD MobileNet v2 320×320, which appears to meet the criteria necessary, after analysing the TensorFlow 2.0 Detection Model Zoo. The architecture has been shown to recognise up to 90 classes and can be customised.
Training the model:
It’s time to think about the training process now that you’ve got a decent dataset and a strong model. The Object Detection API in TensorFlow 2.0 makes it simple to build, train, and deploy object detection models. I’m going to utilise this API and a Google Colaboratory Notebook to train the model.
Setting up the environment:
Select a GPU as the hardware accelerator in a new Google Colab notebook:
Change the type of runtime > Accelerator hardware: GPU
The TensorFlow Object Detection API can be cloned, installed, and tested as follows:
Then, using the appropriate commands, download and extract the dataset:
Setting up the training pipeline
I’m now ready to set up the training pipeline. The following instructions will be used to download pre-trained weights for the SSD MobileNet v2 320×320 on the COCO 2017 Dataset from TensorFlow 2.0:
The downloaded weights were pre-trained on the COCO 2017 Dataset, but as the goal is to train the model to recognise only one class, these weights will only be used to establish the network — this technique is known as transfer learning, and it’s widely used to speed up the learning process.
Finally, on the configuration file that will be utilised throughout the training, set up the hyper parameters. Choosing the best hyper parameters is a task that necessitates some trial and error.
I used a typical setup of MobileNetV2 parameters from the TensorFlow Models Config Repository and ran a series of tests on the SKU110K dataset to optimise the model for tightly packed scenes (thanks Google Developers for the free materials). Use the code below to download the configuration and verify the parameters.
To identify how well the training is going, I am using the loss value. Loss is a number indicating how bad the model’s prediction was on the training samples. If the model’s prediction is perfect, the loss is zero; otherwise, the loss is greater. The goal of training a model is to find a set of weights and biases that have low loss, on average, across all. The training process was monitored through Tensor board and took around 22h to finish on a 60GB machine using an NVIDIA Tesla P4.
Validate the model:
Now let’s evaluate the trained model using the test data:
The evaluation was done across 2740 images and provides three metrics based on the COCO detection evaluation metrics: precision, recall, and loss. The same metrics are available via Tensor board and can be analysed in an easier way. You can then explore all training and evaluation metrics.
Exporting the model:
It’s time to export the model now that the training has been validated. The training checkpoints will be converted to a protobuf (pb) file. This file is going to have the graph definition and the weights of the model.
As we’re going to deploy the model using TensorFlow.js and Google Colab has a maximum lifetime limit of 12 hours, let’s download the trained weights and save them locally. When running the command files. Download (“/content/saved_model.zip”), the Colab will prompt the file download automatically.
Deploying the model:
The model will be distributed in such a way that anyone with a web browser can open a PC or mobile camera and execute real-time inference. To do so, I’ll convert the stored model to TensorFlow.js layers format, load it into a JavaScript application, and make everything publicly available.
Converting the model:
Let’s start by setting up an isolated Python environment so that I may work in an empty workspace and avoid any library conflicts. Install virtualenv, then create and activate a new virtual environment in the inference-graph folder using a terminal:
venv source venv/bin/activate virtualenv -p python3
Install the TensorFlow.js converter by running pip install tensorflow.js tensorflow.js ten [wizard] install tensorflowjs
Start the conversion wizard: tensorflowjs_wizard
Now, the tool will guide you through the conversion, providing explanations for each choice you need to make. The image below shows all the choices that were made to convert the model. Most of them are the standard ones, but options like the shard sizes and compression can be changed according to your needs.
To enable the browser to cache the weights automatically, it’s recommended to split them.
Conclusion:
Apart from the precision, one of the most intriguing aspects of these tests is the inference time – everything is done in real time in the browser using JavaScript. In many consumers packaged goods industry applications, as well as other industries, SKU identification models that run in the browser, even offline, and use low computational resources are a necessary.
Enabling a Machine Learning solution to operate on the client side is a critical step in ensuring that models are used efficiently at the point of interaction with minimal latency and that problems are solved when they occur: right in the user’s hands.
Deep learning should not be expensive and should be utilised for more than just research, with JavaScript being ideal for production deployments. I hope you find this post useful.